統計数理研究所との連携協定、林知己夫先生の"数量化" その1
少し前となりますが、立川の統計数理研究所と、連携協定を結びました。本学からは、間をつないでくれた数学の西村圭一教授、佐々木幸寿理事・副学長と私が赴き、椿広計所長と川端能典副所長にご対応頂きました。
https://www.u-gakugei.ac.jp/pickup-news/2021/04/post-783.html
統計数理研究所には初めて行ったのですが、ああ、ここがかの統計数理研究所か...、という感慨がありました。統計数理研究所は、有名な研究者を数々輩出している世界的な研究所ですが、そうした先生方の中で、1970年代から80年代にかけて所長もお務めになった林知己夫先生には、特別な思いがありました。一面識もありませんが、林先生が開発された"数量化"という手法のおかげで、私は学位論文を書くことができたからです。
"数量化"は、相関という考え方をつかって、多くの変数間の関係を調べる統計手法である多変量解析のひとつです。
私の学位論文では、知的障害を有する人の平均台歩きや片足立ちといったバランス運動の成績が、年齢(生活年齢)、障害の程度を表すIQ、ダウン症や自閉症といった診断名、歩き始めの時期である始歩期というような変数でどのくらい説明されるか明らかにし、そして、それら変数の関与の大きさを比較する必要がありました。この変数の中には、診断名という数量データではないカテゴリー・データが含まれています。こうした場合、よく知られた多変量解析である重回帰分析などはうまくあてはまりません。この点で大分苦しみましたが、数量データとカテゴリー・データが混ざっていても、私が必要としたような分析を行い得るのが、林先生の開発した"数量化"のうちの"数量化Ⅰ類"というものでした。このやり方を知った時には、世界をつかんだような気がしました。"数量化Ⅰ類"での分析を糸口にして、学位論文のストーリーをつくり、まとめることができました。
最近、データ・サイエンスということが盛んに言われており、教育にもそうした考え方の導入を、ということで(何を今頃?とも思いますが)、いろいろなところで統計の簡単な紹介がなされていますが、検定論に多くのスペースが割かれているのを見るとどうかな、と思います。t検定や分散分析といった検定は、よく知られているものですが、これらは推測統計の範疇に入るもので、推測統計では確率計算をしますので、前提としてデータ抽出の手続きー無作為抽出を厳密に行うことが求められます。それが果たされていないとそこから先の分析は意味がありません。心理学はいざしらず、学校や教育の事象では、データを採れるところはそう多くありませんので、データの無作為抽出というのは、かなり困難な手続きです。私は、そうした事象には、無理に推測統計をあてはめず、記述統計を用いたらどうかと思います。記述統計は、代表値やグラフ表記の仕方程度のものと、軽んじられているようにも思いますが、相関係数まで使えば、手元にあるデータについての特徴をすっきりと言うのにかなり役に立つと思っています。ただし、データ抽出の手続きを踏んでいなければ、あくまで手元のデータの整理ということですので、一般的なことまでいうのには、それなりの、別の論理が必要となりますが。
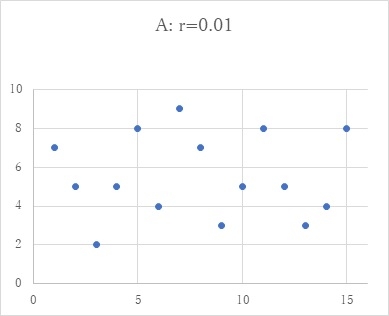
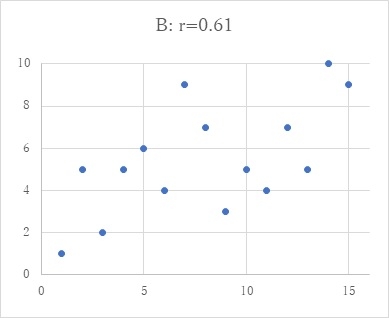
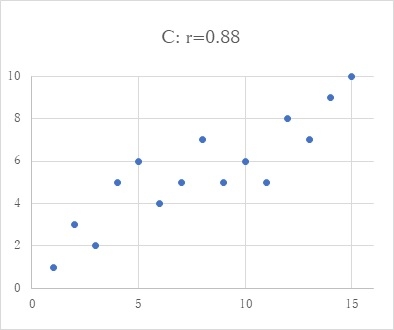
相関係数というのは、2つの変数の相関の程度をあらわすもので、ピアソンの相関係数がよく知られています。これは、2つの変数の相関の程度をマイナス1からプラス1までの間で表します。実際を図によりながら説明しますと、下のAは、2つの変数間に相関がほとんどないというような状態で、データは全体にばらついています。この時の相関係数rは、ほとんど0です。Bの状態は、中程度の相関が2つの変数間にある状態で、データは右上がりにばらつきます。相関係数rは0.61です。2変数間の相関がもっと強いのがCで、相関係数rは0.88です。このように2変数間の相関が強くなると、相関係数は大きくなり、rが1という時には、データは一直線上に乗ります。符号は、相関が右上がりの場合プラス、右下がりの場合マイナスです。相関係数というのは、このように2つの変数の相関の状態を、ひとつの数値で表すことのできる便利なものです。一応、計算式を言いますと、2変数の共分散を、それぞれの変数の標準偏差の積で割るというものです、何のことかいな?という感じとは思いますが、excelでは、関数のひとつとして入っています(=correl(変数1,変数2))。下の図は、これでデータをシュミレーションしながら描いたものです。(この記事続く...)