統計数理研究所との連携協定、林知己夫先生の"数量化" その2
統計数理研究所との連携協定、林知己夫先生の"数量化" その2
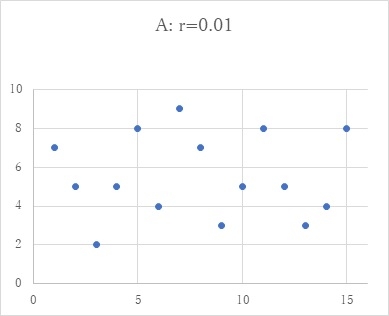
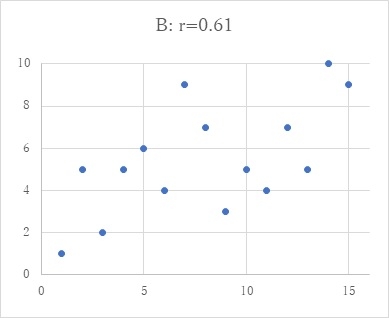
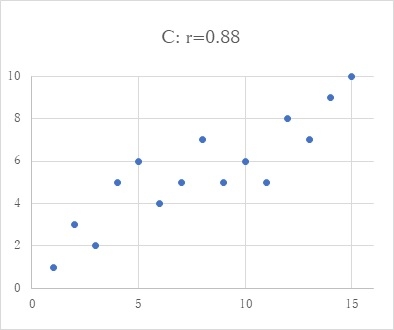
前回記しましたように、相関係数というのは、データの状態を記述するだけのものなので、記述統計の範囲ですが、それを、例えば、前回の図のBのような状態の時に、この0.61という相関が、確かに意味のあるものかどうなのか、言い換えれば、この2変数の関係は、相関が0ではなく、確かに何か意味のある相関があると言いたいとなると(この誘惑は強いものです...)、推測統計の世界に足を踏み出すことになります。これは、相関係数の有意性の検定ということで、2変数間の相関が0という状態の時に、こうした状態(この場合、0.61という相関係数が得られるような事態)が生じる確率を計算することになります。そして、その確率が、100回のうち5回も起こらない稀なことだと計算されれば、この2つの変数間には何か意味のある相関があるのだと判断することになります。こうした計算過程に進む時に求められる前提条件が無作為のサンプリングということで、それがなされていなければ、こうした計算及び判断プロセスは無意味なこととなります。学校や教育の事象では、これが難しいというのは、前回の学長室だよりにも記しました。
前回記しましたように、私を救ってくれた林先生の"数量化Ⅰ類"は、そのデータ処理は簡単ではなく、パソコン等を使わなければ到底無理ですが、種類としては、記述統計とも言えます。私は、検定プロセスには入らずに論文を書きましたが、それで当時(30数年前)の学会誌に査読を通って掲載されました。また、前回少し触れた重回帰分析などの多変量解析も、検定に踏み込まなければ、記述統計として使うことのできるものだと思います。
今本学で進めているカリキュラム改訂の中では、データ・サイエンスの科目も立てることにしています。そこで、この記述統計を中心に、相関係数や多変量解析まで扱う8コマ程度で1単位の授業が構成できるのではないかと思い、シラバスを作り、カリキュラム改訂を担当している佐々木理事・副学長に見せましたが、残念ながら、お眼鏡にかなわず、ボツとなってしまいました(ちゃんと見たのかなぁ?、とも思っているのですが。内心...)、が、心を残しており、いつかどこかでリベンジしたいと思っています。
ちなみに、統計学には、数学以外の研究者・学者が多く関わっています。統計学が"応用"数学とされる所以だと思います。研究所でわれわれに対応してくださった椿広計所長は、工学者で理系の方でしたが、川崎能典副所長は経済学者でした。私が研究室に置いていた統計学のもっとも浩瀚(と思われる)な辞典、東洋経済の「統計学辞典」の編者代表の竹内啓氏も経済学者でした。多変量解析のひとつ、因子分析の開発には心理学者が多く関わっていますし、授業中の課題で、Fの表の見方がわからなくてオタオタしている学部生の私に、机間巡視しながら、悲しげな表情で見るべきところを指差しで教えてくれた東北大学の教育心理学講座にいらした繁桝算男先生は、ベイズ統計の第1人者でした。そう言えば、前回記した相関係数に名前のついているピアソンの師匠筋にあたるフランシス・ゴールトンは、実験心理学及び近代統計学の祖のひとりとされていますが、何学者と言っていいのかわからないような人でした。ご本人的には"優生学者"ということだと思いますが。このダーウィンの従弟にして、イギリスの高級陶器メーカー・ウェッジウッドにつながる、生涯を高等遊民として生きた不思議な奇人とも言えるゴールトンについては、また何かの折に記したいと思います。